Embedding向量质量评估
Embedding算法通常都是无监督的,但是也是需要找到合适的模型评估方法,否则没法迭代模型参数,比如word2vec的window size等
NLP
Embedding算法真正开始发光发热应该是起源于word2vec算法,因此先说说NLP领域的一些评估方法
Analogy
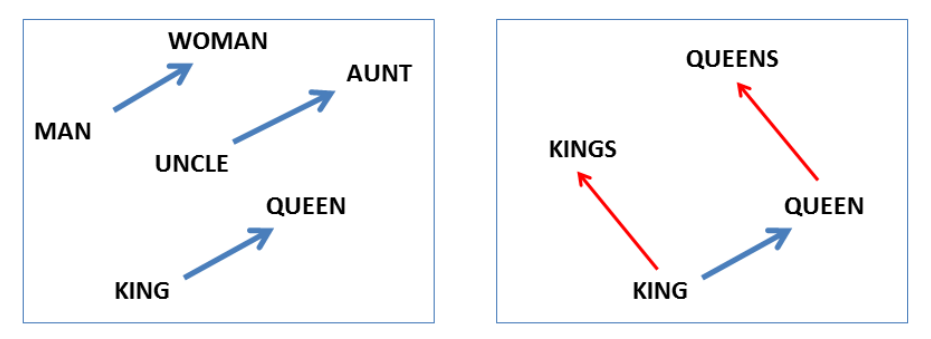
This task was popularized by Mikolov et al. (2013a). The goal is to find a term x for a given term y so that x : y best resembles a sample relationship a : b.
NLP中的Embedding空间有个特点就是类似的词向量会比较接近,因此会产生一个”好玩”的现象,也就是king - queen = man - woman,那么也就可以设计一大批这种类似词的组合来进行模型评估。
数据集
- https://aclweb.org/aclwiki/Analogy_(State_of_the_art)
- https://vecto.space/projects/BATS/
- https://d2l.ai/chapter_natural-language-processing-pretraining/similarity-analogy.html
Rellatedness / Similarity
These datasets contain relatedness scores for pairs of words; the cosine similarity of the embeddings for two words should have high correlation (Spearman or Pearson) with human relatedness scores.
向量相似的体现就是两个词是相关的或者相似的,目前有一些标准的数据集已经提供了一些词对之间的相关度和近似度,比如wordsim353。
wordsim353中数据对样例:
Relatedness
| word1 | word2 | score |
| computer | keyboard | 7.62 |
| Jerusalem | Israel | 8.46 |
| planet | galaxy | 8.11 |
| canyon | landscape | 7.53 |
| OPEC | country | 5.63 |
| day | summer | 3.94 |
| country | citizen | 7.31 |
Similarity
| word1 | word2 | score |
| tiger | cat | 7.35 |
| plane | car | 5.77 |
| television | radio | 6.77 |
| bread | butter | 6.19 |
| media | radio | 7.42 |
| doctor | nurse | 7.00 |
| cucumber | potato | 5.92 |
数据集
- http://alfonseca.org/eng/research/wordsim353.html
- https://aclweb.org/aclwiki/SimLex-999_(State_of_the_art)
Categorization
Here, the goal is to recover a clustering of words into different categories. To do this, the corresponding word vectors of all words in a dataset are clustered and the purity of the returned clusters is computed with respect to the labeled dataset.
Selectional preference
The goal is to determine how typical a noun is for a verb either as a subject or as an object (e.g., people eat, but we rarely eat people). We follow the procedure that is outlined in Baroni et al. (2014).
任务相关
由于Embedding向量经常作为下游深度模型的输入特征使用,因此也可以直接基于下游具体目标任务的指标来作为Embedding模型的优化目标。但是这种端到端的调参方式可能效率不高,因此也可以对Embedding向量做些聚类,然后分析轮廓系数之类的方法。
评论系统未开启,无法评论!