Spark SQL中的Window函数
在使用spark sql的时候经常会计算一些汇聚特征,比如一个卖家在一段时间的销售总额,对于这种汇聚后返回单值的需求通过groupBy(“xxx”).agg(“xxx”)即可。
但是有些时候需要计算一些排序特征,窗口特征等,如一个店铺的首单特征。对于这样的特征显然是不能简单通过groupBy操作来完成,好在spark提供了window函数来完成类似的操作。
window函数对于DataFrame中的每一行都返回一个计算出的值,而groupBy则是对于一个group的key返回一个值。对于DataFrame中的每一行,WindowSpec指定了这行对应的一个WindowFrame,然后在这个WindowFrame上执行相关统计函数。
样例代码
1 | val orders = Seq( |
订单顺序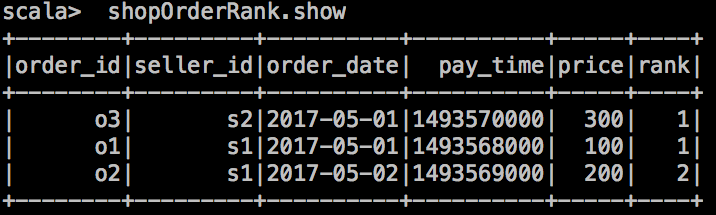
窗口累加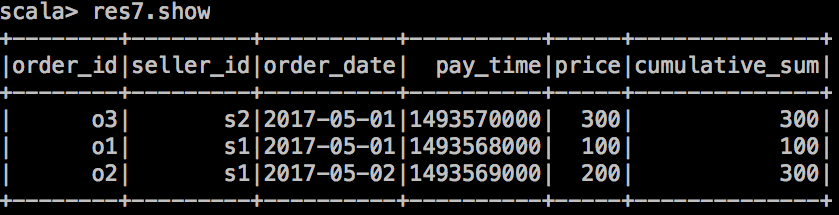
相关链接
https://databricks.com/blog/2015/07/15/introducing-window-functions-in-spark-sql.html
评论系统未开启,无法评论!